Issue 78: uMatrix: voyuering the voyeurs
Published:
Previously: The default settings of most browsers expose a lot of information to scripts that request it. To prevent such scripts from running, we need services that can filter the source of these scripts. These services generally work by matching browser requests against a blacklist, and blocking the request if it comes from a domain known to host malicious scripts.
Many existing solutions to blocking scripts—let’s call them script-blockers—rely on manually managing a blacklist. That is to be expected, but few of them make it easy to see which domains the scripts are coming from.
uMatrix
As part of my research for this season, I installed uMatrix, a browser extension for Firefox, Chrome, and Opera.
Once installed, it adds a button beside the address bar. When clicked, this button pops up a matrix showing the number of resources loaded from each domain:
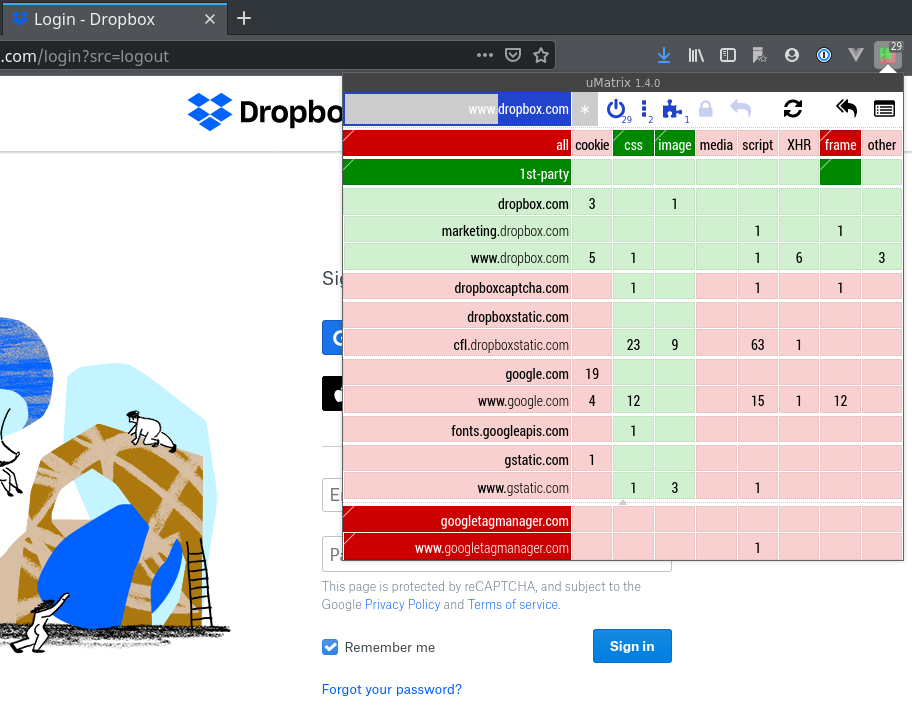
uMatrix in Firefox showing default settings.
Items highlighted in green are permitted to load, items in red are blocked.
Understanding the Matrix
Along the top row, the column headers tell us what kind of resources are being requested by the page. A quick refresher:
- cookies are little bits of information that scripts attach to a domain in the browser (Issue 69))
- CSS (Cascading Style Sheet) files describe the styling to be applied to the page
- image files need no explanation I hope
- media covers any rich/animated media e.g. videos
- scripts are javascript files containing code to be executed when the page has loaded them
- XHR (XmlHTTPRequests) are requests for other resources—to verify a Captcha, get a winning ad bid (Issue 73)) … or something as innocent as getting the weather forecast
- frame refers to iframes (inline frames), which are a way of embedding a webpage inside another. You see this often on sites which display PDF files within their pages. But this can also be used to embed Captcha puzzles within a login box, for instance.
- other: I won’t go into the other esoteric means of loading data onto a webpage; we won’t need that for this issue
At a glance, I can see that just to load the login, the Dropbox webpage is pulling resources not only from dropbox.com, but also from:
- dropboxcaptcha.com
- dropboxstatic.com
- google.com
- fonts.googleapis.com
- gstatic.com
- googletagmanager.com
These are represented as row labels.
The numbers in each cell represent how many resources of each type are being loaded from each domain.
CSS and images are considered important and quite harmless, and are thus allowed by default. First-party resources (Issue 76)) too, since the website itself has full control over them, are considered “secure”, assuming you trust that website enough to be there in the first place.
Blacklisting or whitelisting domains
By default, some domains known to host scripts for tracking are already blacklisted. googletagmanager.com (highlighted in bold red) is the domain for Google’s Tag Manager platform for measuring and analysing browsing data. It is how their ads can get personalised data on you, so it is on uMatrix’s blacklist once you install it.
Other third-party domains are blacklisted by default (highlighted in light red) for your safety, but I can choose to whitelist them by clicking on them until they are highlighted in light green.
Dissecting page functionality
That’s interesting … blocking all third-party resources does not stop the page from loading at all! So what are those resources doing (especially the 63 scripts from cfl.dropboxstatic.com)? Let’s continue using the webpage to find out.
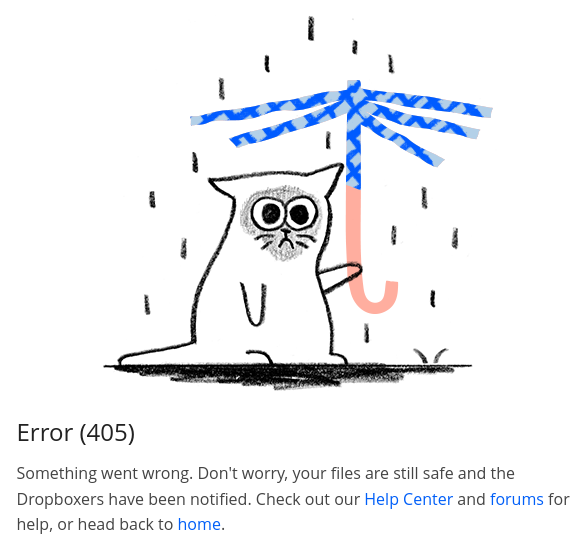
Error (405) means Method Not Allowed, implying that something is missing from the webpage resulting in it not understanding what to do. Oops.
Error 405. Looks like I broke something. This is the tedious part: I whitelist one domain at a time, reloading the page each time to see if anything changes.
It turns out the Dropbox webpage is doing a surprising number of things behind the scenes! By the time I managed to get a login, uMatrix looked like this:
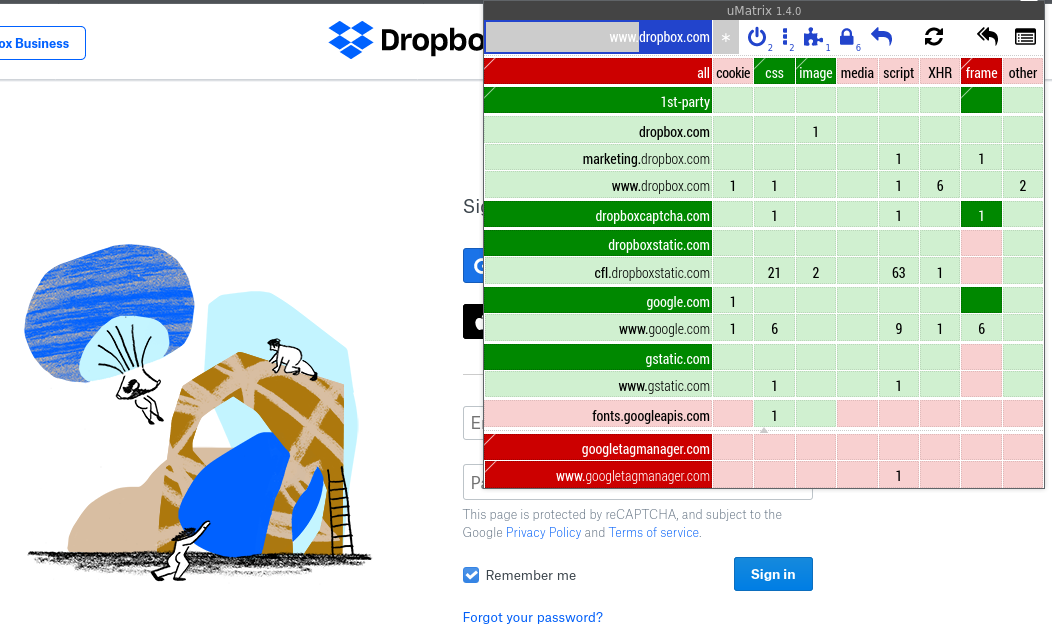
uMatrix in Firefox showing settings that got Dropbox working.
I had to allow embedded frames from dropboxcaptcha.com and google.com as well.
Spotting the patterns
If you are thinking of trying this, be warned: this will frustrate your browsing experience for the first week or so (after you take a couple of days to figure out how the uMatrix interface works) while you build up a custom whitelist of domains on your usual online haunts. There is an “off” button for times when you really don’t have the brainspace to be figuring this out (e.g. when you are just tying to get some ibanking done quickly), but it shouldn’t be the default setting.
I did this because I wanted to know what my web browser is doing. And here are some things I’ve figured out through this exercise:
- Big websites often load their unchanging (static) resources, such as images, CSS files, script files, etc, from a separate domain.
Presumably they do this so that this other domain can be set up for caching (Issue 39)). Having static files cached on the browser makes the browsing experience much smoother, as static parts such as the icons and stylesheets can be rendered (put on screen) first while waiting for dynamic data to load.
Dropbox loads their static resources from dropboxstatic.com. - Big websites may load their dynamic data from a CDN (Issue 73)).
Once traffic gets large enough that a single server might not be able to handle peak load, many online services switch to delivering their content through a CDN (such as Squarespace). These resources will appear to be loaded from a third-party. So anything with a “cdn” in the domain is probably safe. - ReCaptchas don’t always need a pop-up.
Some of them run in the background, checking to see if you have already been verified human somewhere else, or verifying you by other means.
Dropbox loads its captchas from dropboxcaptcha.com and google.com (for Google’s reCaptcha service). Two layers of captchas! - There are many websites out there that rely on google.com being whitelisted. This is what happens when you have a single company providing so many critical services that their domain has to be whitelisted. If blocked, the webpage will no longer work.
- Some websites rely on “daisy-chaining”, where script A loads script B which loads script C, and so on.
You know this because when using uMatrix, you whitelist a domain and reload the page, and another domain appers. You whitelist that domain, and another one appears …
Issue summary: Modern webpages rely on many third-party resources for their functionality. Blocking access to some domains may cause these webpages to break and stop working.
This was fun, in a masochistic sort of way. Most of what I learnt here is not really newsletter-worthy: how prevalent Google is, what a clean webpage looks like in the backend (very few domains), what a massive webpage looks like (lots of domains! E.g. Trello), what the most popular CDNs are, and some dead giveaways of a webpage quickly spiralling out of control (large numbers on a single domain, slow loading with no static domain or CDN) … maybe I’ll figure out the layman-worthy parts of it someday and put it in another season.
What I’ll be covering next
Next issue: [LMG S7] Issue 79: A Base for Data
Next season, we go back to data again. Specifically, we look at how data is stored and managed for most of the internet: in a database.
What is a database and why do we need one?
Sometime in the future: What is:
- booting up? [Issue 15]
- XSS? [Issue 8]
- a good reason developers write code and give it away for free online? [Issue 21]
- firmware? [Issue 34]
- OpenType? And what are fonts anyway? [Issue 42]
- What is involved in installing a piece of software? [Issue 48]
- How do apps know where a file starts and ends? [Issue 49]
- What is a password hash? [Issue 63]