Issue 172: Tokens, the currency of LLMs
Published:
Previously: The Transformer architecture, unlike previous machine learning model architectures, could generate its next item while processing all previous items at the same time. The technique of unsupervised learning trained models on unlabelled data, letting the model pick up patterns in underlying data instead of having it learn correct answers only, and was much faster than supervised learning. OpenAI applied both these ideas at scale, producing GPT-1, a model that beat best-performing models while requiring relatively little human supervision during training.
Wait—what exactly does a large language model (LLM) work with? Individual letters? Entire words? No, they work with—
Tokens
Tokens are clusters of letters that make up the training data. The large language model (LLM) does not “see” letters or words, only tokens.
Tokens are … quite unlike phonemes, syllables, or other word-fragments you and I are familiar with. They are typically programmatically generated by a separate program (not a model), based on letter-clusters that appear most frequently in the data.
For example, using OpenAI’s Tokenizer tool to visualize the above paragraph gives us this:
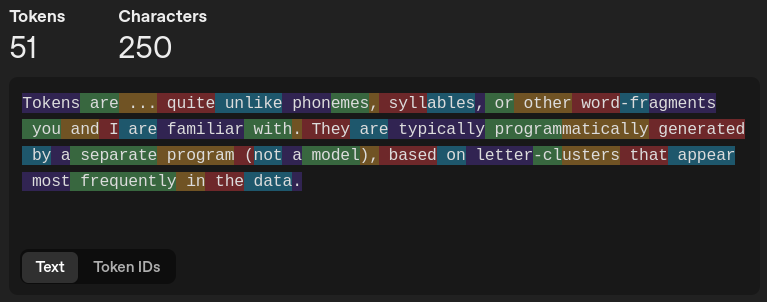
OpenAI Tokenizer - text view
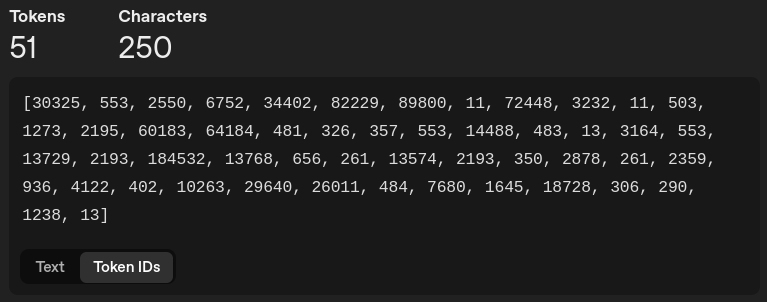
OpenAI Tokenizer - token ID view
There is little human-discernible pattern as to what definitively constitutes a token: it could be a single punctuation mark, a letter or two (and sometimes including their preceding space, sometimes not), or an entire word.
Whatever the case, what we see as " you and I", a LLM sees as [481, 326, 357]. A pre-tokenizer program tokenizes all input into numerical values.
Now you understand a little better why ChatGPT struggles to count Rs in “strawberry”, or in any other fruit really.
Embeddings
How does the model tell 481, 326, and 357 apart? How does it store or represent them within itself? Here, I am going to need you to use your imagination. You are familiar with the concept of a scatter plot, yes? A graph that looks like this:
A scatterplot with 2 dimensions
Source: EmbeddedSource
Now imagine a scatterplot with as many data points as tokens. In GPT-1’s case, that’s approx. 40,000 tokens—its vocabulary size. Yes, I know that’s a lot of points, but you can roughly visualize that, yes? Good, that’s the easy part.
Now I need you to imagine the scatterplot with … *checks notes*—768 dimensions. No, that is not a typo, we are talking about a scatterplot with 768 dimensions. Oh, that’s too difficult to imagine? Yeah. Sorry, that’s why I don’t have an image attached. Just try your best 🙏
Essentially that is what a LLM generates as a result of its training. Each token in its vocabulary becomes a data point, and each data point is represented in this 768-dimensional space using 768 decimal numbers ranging from 0 to 1.0. This positional representation using many decimal numbers is called an embedding.
Other uses for embeddings
Embeddings are also not a new idea: they precede GPT by decades, having been conceptualized as early as the 1980s.
Because they’re such a handy and intuitive mathematical way to represent or visualize tokens and semantics, they’re also used often in semantic search engines (which try to infer what you mean instead of what you said), recommendation engines (suggesting similar things based on what you bought or liked), relevance scoring, etc.
How a LLM represents semantics
There’s more to a LLM than this collection of 40,000 embeddings; it forms only a tiny fraction of the entire model. But it is critical to how the LLM “learns” information from the text. Based on where the tokens appear relative to each other in the text, and the higher-order patterns that the model detects through its hidden layers, the model adjusts the embedding for each token, placing semantically similar ones closer to each other and dissimilar tokens farther away from each other.
And because this is a mathematical space with direction (in 768 dimensions), the model can also pick up on analogy to some extent: if you draw a (768-dimensional) arrow pointing king → queen and another arrow pointing father → mother within this embedding matrix, they end up almost parallel. This means the model can solve SAT vocab pairs, giving you “mother” when you give it “king:queen, father:?”
If an LLM relied only on this embedding matrix, it would not be able to distinguish “bat” as a warm flying mammal from “bat” as a piece of sporting equipment. The rest of the model—using the Transformer architecture, you’ll recall from issue 171—uses the tokens surrounding it and their positions to infer the context that “bat” is being used in.
Model pricing and limits
Most ChatGPT/Claude users are familiar with those products as subscriptions, where they pay a certain price per month to use ChatGPT/Claude for some arbitrary amount, and if they use too much too quickly they hit a usage limit and have to wait for it to reset.
But if you are a business, and using the API instead, you’ll be looking at a different page, such as the API pricing page for OpenAI’s API. Notice that prices are typically quoted in units of “1M tokens”, standing for “1 million tokens”. Now you know what those tokens are referring to.
Likewise, when Anthropic explains how usage and length limits work, and tell you that “Claude’s context window is 200K tokens”, you now know what they are referring to. More importantly, you know it doesn’t mean 200 characters or 200 words.
Issue summary: A model does not see letters or words, only tokens. These tokens are typically generated from user input through a pre-tokenizer program. Tokens are represented in the model as embeddings, a sequence of numbers representing the token’s position in the embedding matrix. The model uses each token’s embedding, and its surrounding tokens, to infer its meaning in context.
I would have gone on longer, but I think tokens are a pretty novel concept for most layfolks and deserve their own issue to sit with and digest before we talk about what a model does.
What I’ll be covering next
Next issue: Issue 173: Training, Inference, and Scaling